





El reconocimiento óptico de caracteres o OCR (Optical Character Recognition), es un proceso dirigido a la digitalización de textos, los cuales identifican automáticamente a partir de una imagen símbolos o caracteres que pertenecen a un determinado alfabeto.
En este post se explica cómo implementar el reconocimiento óptico de caracteres para imágenes con Tess4J el cual es un contenedor basado en JNA (Java Native Access) para Tesseract OCR API, la biblioteca proporciona soporte de reconocimiento óptico de caracteres (OCR) para:
Descarga e instalación
Puedes usar Tess4J desde Maven:
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j --> <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.4.0</version> </dependency>
o descargar la librería desde este enlace Tess4J-3.4.8-src.zip son 30.7 MB
Ejemplo con Netbeans
Crea un proyecto java con netbeans el cual llamaremos «Ejemplo Tess4J», agrega la librería con todas sus dependencias, si usas maven este paso ya no es necesario.
La imagen que utilizaremos de ejemplo es la siguiente:

También necesitamos los archivos *.traineddata correspondientes al lenguaje que deseamos utilizar, puedes descargar estos desde https://github.com/tesseract-ocr/tessdata o https://github.com/tesseract-ocr/tessdata/tree/3.04.00 dependiendo de la versión de Tess4J que estés utilizando. El archivo que descargaremos es spa.traineddata (15.6 MB) para el lenguaje español, código «spa».
Colocaremos la imagen PNG en el directorio raíz de nuestro proyecto y los archivos traineddata en una carpeta con el nombre de «tessdata«, es decir:
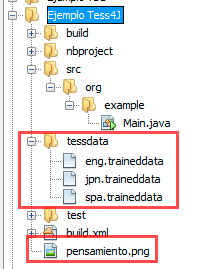
Ahora en la clase Main colocaremos el siguiente código:
package org.example; import java.io.File; import net.sourceforge.tess4j.*; /** * @author Tess4J */ public class Main { public static void main(String[] args) { File imageFile = new File("pensamiento.png"); ITesseract instance = new Tesseract(); // JNA Interface Mapping // ITesseract instance = new Tesseract1(); // JNA Direct Mapping instance.setLanguage("spa");//lenguaje //por defecto busca los archivos traineddata en la carpeta tessdata //ubicada en la raiz del proyecto, si utilizas otra dirección, //debes indicar la ruta con este metodo //instance.setDatapath("/tessdata"); // dirección de los archivos tessdata try { String result = instance.doOCR(imageFile); //impresión del resultado System.out.println(result); } catch (TesseractException e) { System.err.println(e.getMessage()); } } }
Y al ejecutar tenemos:
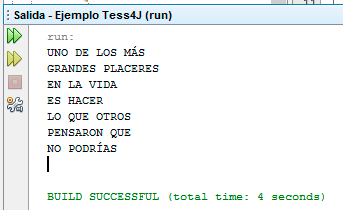
enjoy!

¿Quieres iniciarte en la programación? ¿Eres un programador impaciente que odia instalar cualquier software en su comput[...]

ASCII acrónimo inglés de American Standard Code for Information Interchange (Código Estándar Estadounidense para el Inte[...]
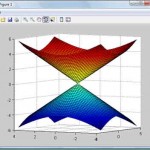
1. En la ventana de comandos de matlab escribe «mbuild -setup«, sin comillas y presiona enter. >> mbuild -setup We[...]
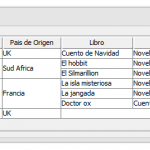
El JTable de Java es un gran componente para mostrar datos en una tabla de una forma rápida y sencilla, sin embargo en v[...]
Cuarta parte de esta pequeña serie de tutoriales sobre [Crea tu blog con el patrón MVC y php] En esta cuarta entrega ver[...]
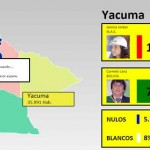
La tecnología de HTML5 y javascript nos permite crear gráficos interactivos livianos sin tener que recurrir a flash, el[...]