





imgclip es una pequeña herramienta de línea de comandos el cual se ejecuta desde la terminal para Mac, Windows y Linux. Imgclip usa la biblioteca Tesseract.js (esta biblioteca admite más de 100 idiomas, orientación automática de texto y detección de guiones, una interfaz simple para leer cuadros delimitadores de párrafos, palabras y caracteres) para automatizar el procesamiento de imágenes y extraer texto a través de OCR (Reconocimiento Óptico de Caracteres). Tesseract es una de las bibliotecas de OCR más potentes hasta la fecha, y es de código abierto como imgclip.
INSTALACIÓN
Se puede instalar desde npm de la siguiente forma:
npm install -g imgclip
Importante: Solo es compatible con Node v6.8.0 +
USO
Usage: imgclip PATH [options] Options: -h, --help output usage information -V, --version output the version number -l, --lang [language] language of the text in the image. -c, --clean-up removes the generated language data file (.traineddata) after the image recognition job has finished -p, --print prints out the text in the image.
Simplemente toma un argumento para el archivo de imagen junto con el idioma (opcional), luego devuelve el texto copiado en el portapapeles.
Por ejemplo, utilizamos una imagen en formato JPG con un texto sencillo, «JC MOUSE», utilizamos imgclip desde linea de comandos junto al parámetro «-p» para imprimir en pantalla el resultado. Obtenemos:
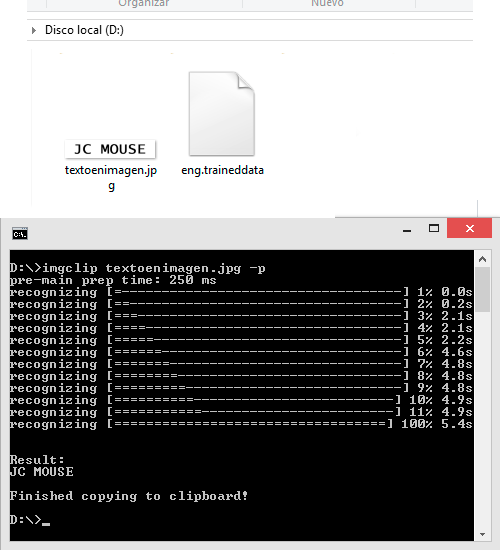
El texto extraído es el correcto, ademas notemos que se crea un archivo «eng»con extensión *.traineddata el cual corresponde al lenguaje utilizado para el reconocimiento de caracteres, por defecto el ingles. Puedes ver la lista completa de idiomas en Tesseract Languages.
Otro ejemplo:
Compliquemos algo más las cosas y utilicemos una imagen con mucho más texto y una imagen de fondo, es decir:
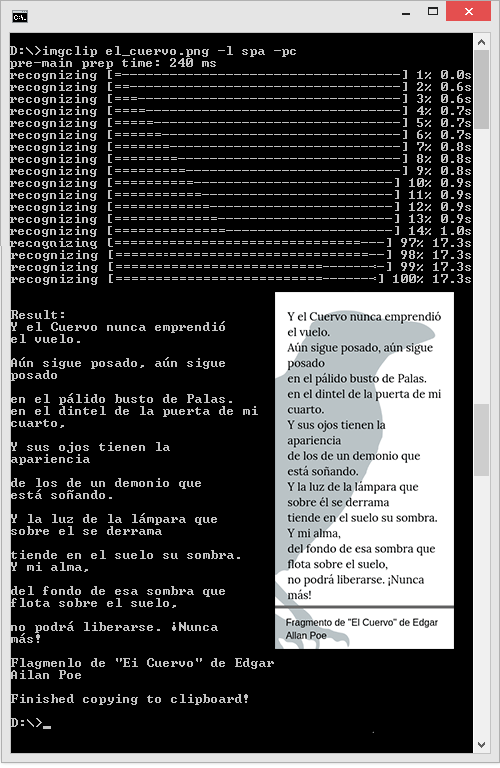
Utilizamos ahora el comando «-l spa» para utilizar el lenguaje español, también los comandos «-pc» para imprimir el resultado en pantalla y eliminar el archivo *.traineddata una vez termine el proceso.
Tenemos más de un 90% de efectividad lo que es algo bueno tomando en cuenta el tamaño y simplicidad de esta herramienta.
enjoy!


Aplicación en Java realida con el IDE de Netbeans 6.9 para trabajar con images en Base de Datos en Access 2003, el progr[...]
Mensajes ocultos utilizando el método de Inserción en el bit menos significativo (Least Significant Bit Insertion) El mé[...]
En esta oportunidad dejo a consideracion un proyecto para la captura de video desde una webcam, utilizando filtros como[...]

En este post te enseñamos a crear tus imagenes al estilo de Disney Pixar utilizando Inteligencia Artificial de una maner[...]

Estructura Interna de un archivo SVG. <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE svg PUBLIC "-//W3C//DTD[...]
Modelo Vista Controlador (MVC) es un patrón de arquitectura de software que separa los datos de una aplicación, la inter[...]