





OCR (Optical Character Recognition) en español, Reconociminto Optico de Caracteres, es el proceso por el cual se extrae texto de imágenes. En este post veremos un ejemplo sencillo de como instalar y utilizar una herramienta OCR de código abierto en el Sistema Operativo Linux Ubuntu.
Tesseract es uno de los motores OCR de código abierto más potentes disponibles en la actualidad. Es compatible con muchos lenguajes, más de 100 (incluido el español) ademas tiene un código establecido para que también se pueda entrenar fácilmente en otros idiomas. El software se ejecuta a través de la línea de comando, es decir, no cuenta una GUI (Interfaz Gráfica de usuario), pero hay varios paquetes de software para Tesseract que proporcionar una interfaz GUI para este OCR.
INSTALACIÓN
Simplemente debemos ejecutar el siguiente comando:
$ sudo apt-get install tesseract-ocr
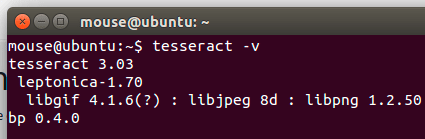
Para comprobar la correcta instalación, escribimos «tesseract -v» esto nos mostrara la versión del OCR junto con una lista de librerías de imagen con las que tesseract es compatible.
INSTALACIÓN DE LENGUAJES
Tesseract por defecto utiliza el ingles y es el idioma que se instala cuando instalas la herramienta, para ver un listado de los idiomas disponibles, ejecuta el comando:
$ tesseract --list-langs
Para instalar un lenguaje determinado se usa «apt-get install tesseract-ocr-LANG» donde LANG son las iniciales del lenguaje que se desea instalar, es decir, para instalar español utilizamos:
$ sudo apt-get install tesseract-ocr-spa
para instalar todos los lenguajes utilizamos:
$ sudo apt-get install tesseract-ocr-all
RECONOCIMIENTO DE CARACTERES
Antes de usar imágenes que contengan texto con Tesseract, las mismas deben ser procesadas, es decir, las imágenes deben estar libres de ruido, sin bordes o gráficos las cuales puedan ser confundidos erróneamente como caracteres, el texto de la imagen no debe estar inclinado, a más inclinación más perdida de precisión, se recomienda también utilizar imágenes en escala de grises o blanco y negro para mejorar la precisión del OCR, para procesar imágenes, se utilizan otras herramientas aparte de Tesseract, por ejemplo Imagemagick, pero esto queda fuera de los objetivos de este post por lo que para la creación de imágenes que contengan texto, podemos usar algún software gráfico o alguna herramienta online como «https://text2image.com/en/«.
Pues bien, utilizando alguna de las herramientas arriba mencionadas, creamos una imagen con un poco de texto.

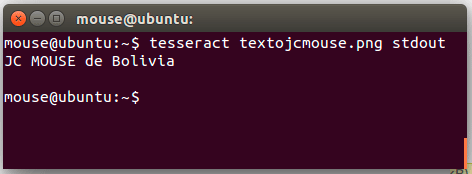
Nos ubicamos en el directorio donde esta nuestra imagen y escribimos «tesseract NOMBRE_ARCHIVO OPCIONES», es decir:
$ tesseract textojcmouse.png stdout
Si queremos guardar el resultado en un archivo de texto, utilizamos:
$ tesseract textojcmouse.png textosalida
Si nuestra imagen contiene números, añadimos la opción «digits«, es decir:
$ tesseract textocondigitos.png stdout digits
enjoy!

Cuando Android estaba en sus inicios, varios IDEs (Entorno de Desarrollo Integrado) se disputaban el dominio por su de[...]

El IDE Netbeans al igual que Eclipse :), nos permite personalizar el espacio de trabajo y añadir funcionalidades que nos[...]

Create Block Theme es el plugin oficial de WordPress para la creación y exportación de «Temas de Bloques» (Block Themes)[...]
La tecnología de HTML5 y javascript nos permite crear gráficos interactivos livianos sin tener que recurrir a flash, el[...]
Yachaywasi versión 3.1 es una aplicación para android que te permite crear, editar y realizar exámenes tipo test cómodam[...]
FFmpeg es una colección de software libre capaz de decodificar, codificar, transcodificar, mux, demux, transmitir, filtr[...]