





OCR (Optical Character Recognition) en español, Reconociminto Optico de Caracteres, es el proceso por el cual se extrae texto de imágenes. En este post veremos un ejemplo sencillo de como instalar y utilizar una herramienta OCR de código abierto en el Sistema Operativo Linux Ubuntu.
Tesseract es uno de los motores OCR de código abierto más potentes disponibles en la actualidad. Es compatible con muchos lenguajes, más de 100 (incluido el español) ademas tiene un código establecido para que también se pueda entrenar fácilmente en otros idiomas. El software se ejecuta a través de la línea de comando, es decir, no cuenta una GUI (Interfaz Gráfica de usuario), pero hay varios paquetes de software para Tesseract que proporcionar una interfaz GUI para este OCR.
INSTALACIÓN
Simplemente debemos ejecutar el siguiente comando:
$ sudo apt-get install tesseract-ocr
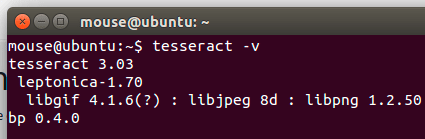
Para comprobar la correcta instalación, escribimos «tesseract -v» esto nos mostrara la versión del OCR junto con una lista de librerías de imagen con las que tesseract es compatible.
INSTALACIÓN DE LENGUAJES
Tesseract por defecto utiliza el ingles y es el idioma que se instala cuando instalas la herramienta, para ver un listado de los idiomas disponibles, ejecuta el comando:
$ tesseract --list-langs
Para instalar un lenguaje determinado se usa «apt-get install tesseract-ocr-LANG» donde LANG son las iniciales del lenguaje que se desea instalar, es decir, para instalar español utilizamos:
$ sudo apt-get install tesseract-ocr-spa
para instalar todos los lenguajes utilizamos:
$ sudo apt-get install tesseract-ocr-all
RECONOCIMIENTO DE CARACTERES
Antes de usar imágenes que contengan texto con Tesseract, las mismas deben ser procesadas, es decir, las imágenes deben estar libres de ruido, sin bordes o gráficos las cuales puedan ser confundidos erróneamente como caracteres, el texto de la imagen no debe estar inclinado, a más inclinación más perdida de precisión, se recomienda también utilizar imágenes en escala de grises o blanco y negro para mejorar la precisión del OCR, para procesar imágenes, se utilizan otras herramientas aparte de Tesseract, por ejemplo Imagemagick, pero esto queda fuera de los objetivos de este post por lo que para la creación de imágenes que contengan texto, podemos usar algún software gráfico o alguna herramienta online como «https://text2image.com/en/«.
Pues bien, utilizando alguna de las herramientas arriba mencionadas, creamos una imagen con un poco de texto.

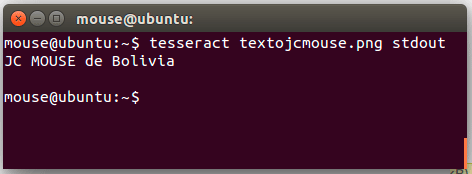
Nos ubicamos en el directorio donde esta nuestra imagen y escribimos «tesseract NOMBRE_ARCHIVO OPCIONES», es decir:
$ tesseract textojcmouse.png stdout
Si queremos guardar el resultado en un archivo de texto, utilizamos:
$ tesseract textojcmouse.png textosalida
Si nuestra imagen contiene números, añadimos la opción «digits«, es decir:
$ tesseract textocondigitos.png stdout digits
enjoy!

im4java es una interfaz pura de Java para la línea de comandos de ImageMagick. La interfaz de la línea de comandos de IM[...]

simuladorasamblea.bo es una herramienta digital desarrollado por los Analistas de Datos Rafael López Valverde y Sergio[...]
Gallery.io es una herramienta de colaboración gratuita desarrollada por Google para cargar trabajos de diseño, obtener c[...]

En el desarrollo web la elección de un buen editor de texto enriquecido (WYSIWYG) es una decisión crucial que afecta dir[...]

The Peanuts Movie fue la película animada de Snoopy & Charlie Brown personajes principales de la serie de tiras cóm[...]

En este post veremos paso a paso como importar registros de archivos *.CSV a una base de datos (MySQL por ejemplo) usand[...]